Data Cleaning & Preparation - SQL
Introduction - data explaination
Data I am going to work on is Dublin Housing. It contains house sales information like date of transaction,
price, property address, name and address of the owner and few more.

Looking at the raw data, I noticed a few places where data could be improved
Date
Sale date in the file is with time format which is not necessary, does not look 'clean' and may introduce issues if we would like perform any analysis based in date frame.
Starting from selecting 'SaleDate' and converted (stripped from time addition) copy of it,
I added column at the end of the table and populated it with converted SaleDate.
The original column could be deleted but I decided to leave it.
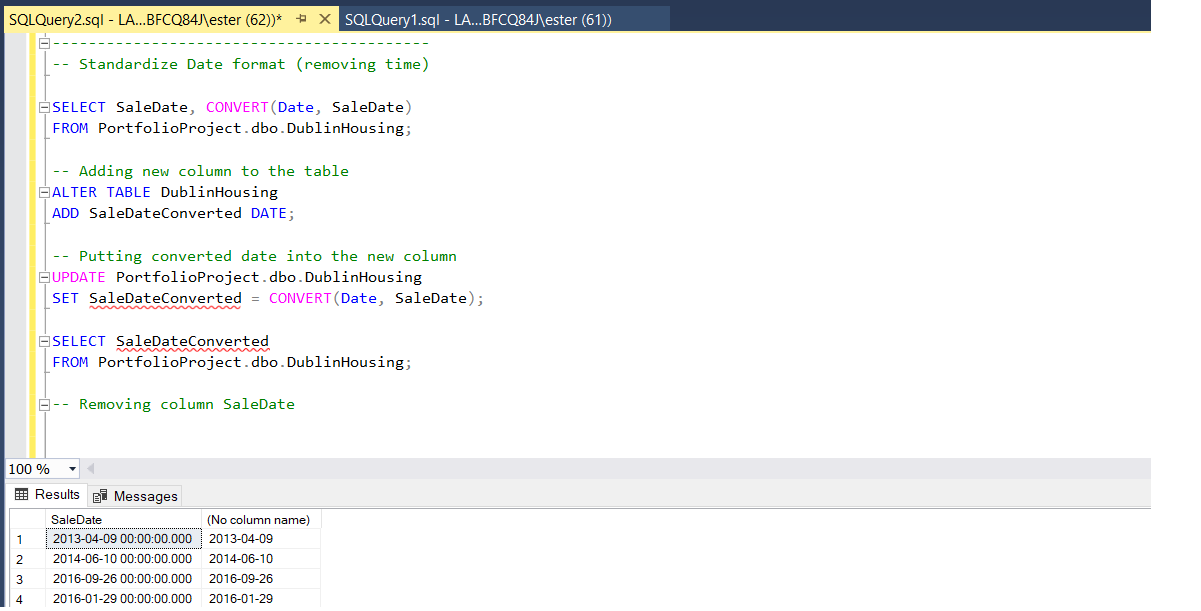
Now I have clean date of sale which is much more
Property Address - Checking for missing values
Since whole data is about property sales, it is extremely important to have information such as property address, therefore I
check for NULL values in 'PropertyAddress' column.
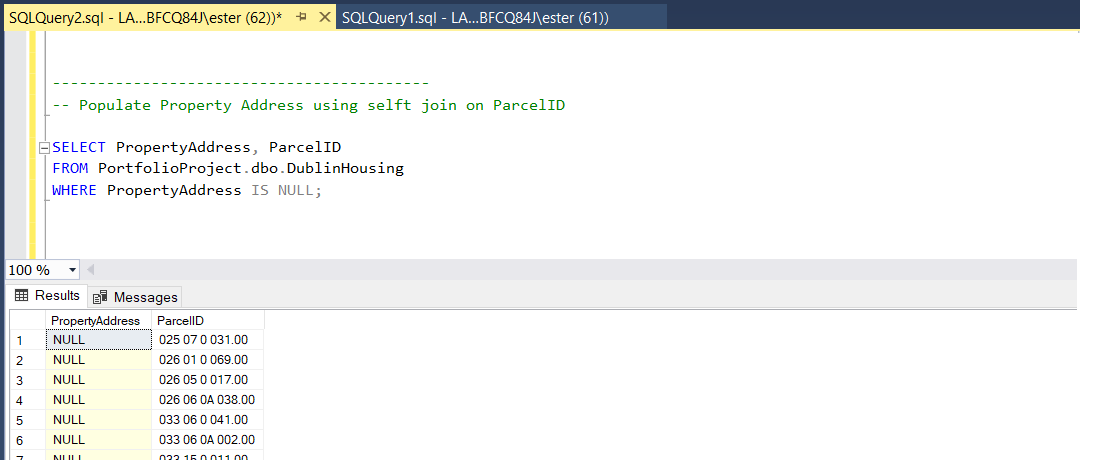
Results shows that there are some missing fields which must be populated or (if population will fail) further investigated.
First, I selected all data to find any matching points, and found out that properties with the same ‘ParcelID’ having the same’ PropertyAddress’.
Using self-join I joined table with itself using ‘ParcelID’ and put under condition – SQL will copy ‘PropertyAddress’ only if ‘UniqueID’ will be different.
Means, it will join table where 'ParcelID' is the same but it is not the same row.
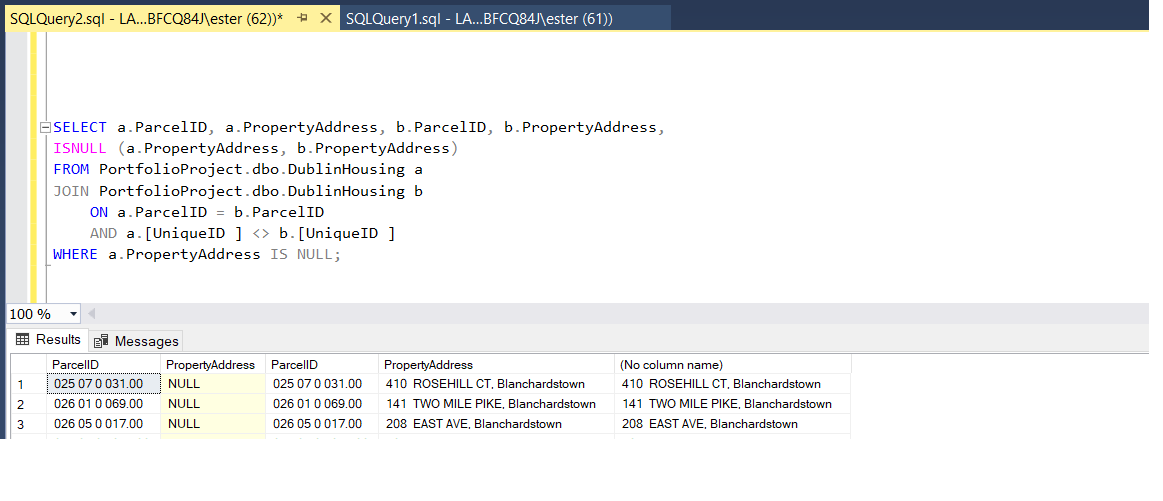
Now I selected property address where is null and copy.
After updating a table, I requested again for a Property Address column where IS NULL and receive blank table. This means that my update was successful, there is no missing addresses in the table.
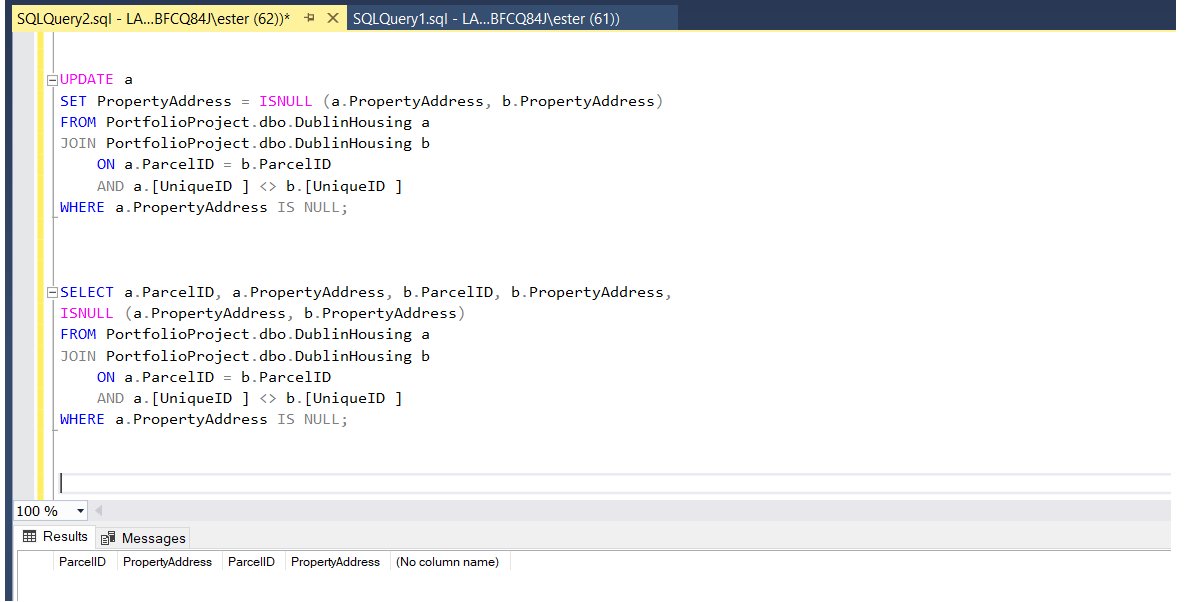
There are no missing values in 'PropertyAddress' column.
Property Address - Dividing the Address method 1
When address is clustered in one field it is hard to pull informative insights like, for example, in which town people buying/selling properties the most.
This type of information may be used in many different ways, as an possible investment area, marketing location, new branch location etc., which might be beneficial for company.
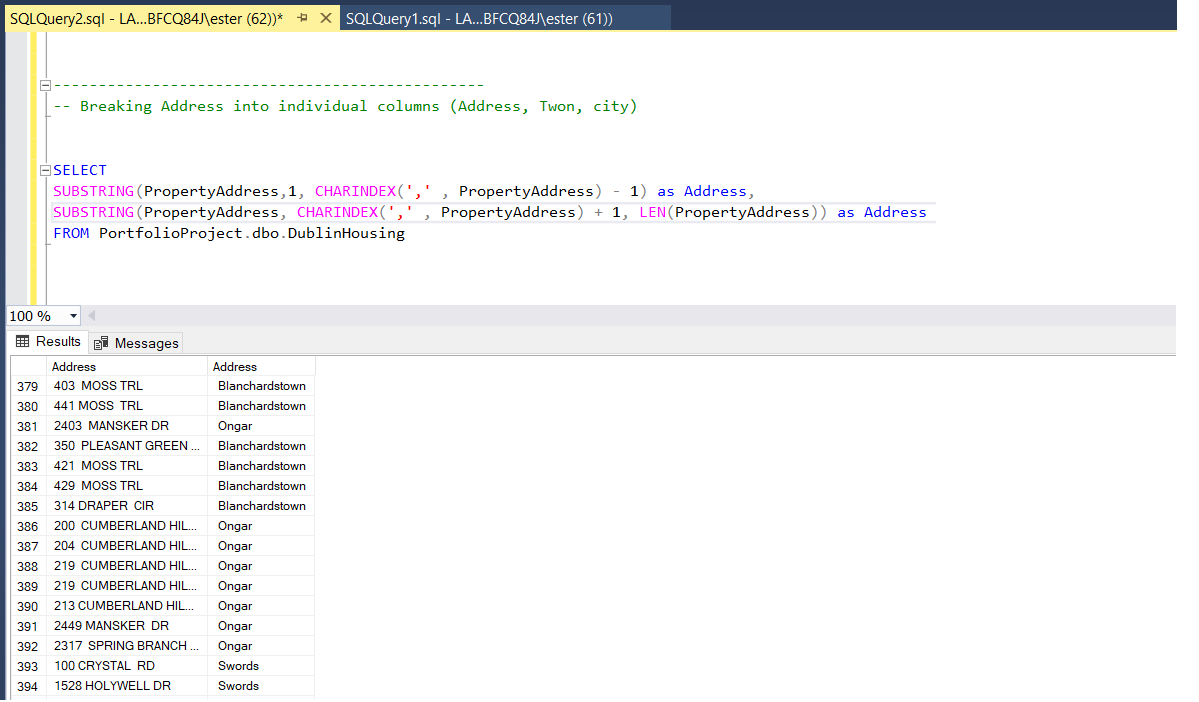
I used Substring as a methodd to devide 'PropertyAddress'. Starting from first character of the string, until coma sign, will be the main address for property. Adding '-1' will remove coma sign after first part of the address.
In second line of SUBSTRING I called 'PropertyAddress’ and started from: coma placement +1, which will read all characters behind coma in the string.
Lastly I need to specify when it has to end. Addresses ussually have different numbers of characters and I do not want to guess, or count what is the longest, therefore I request to end at the lenght of each address string, len().
At the end I added to the table new columns, basic address as ‘PropertySplitAddress’ and Town as ‘PropertySplitTown’.

Owner Address - Dividing the Address method 2
I will split Owner Address as well but this time will use much faster and easier method PARSENAME(). Since PARSENAME() is works only for periods, I am replacing comas sign with periods.
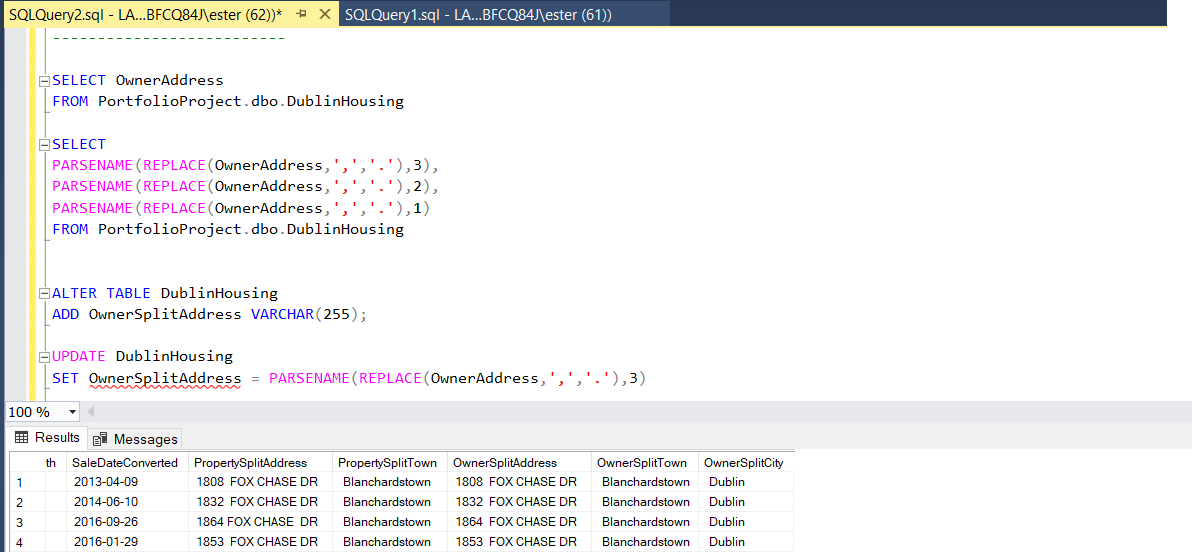
Once again I am altering table. Now data is much more useful.
Formatting 'Yes' and 'No'
Having multiple ways for answers 'yes' and 'no' can create issues in further analysis. Luckly SQL is not case sensitive and will understands word even if is written from small or capitol letter, but for more esthetical look
formatting these type of answers is a good practise and , moreover we can change if someone input 'y' instead of 'yes' and solve future problem right at the base.
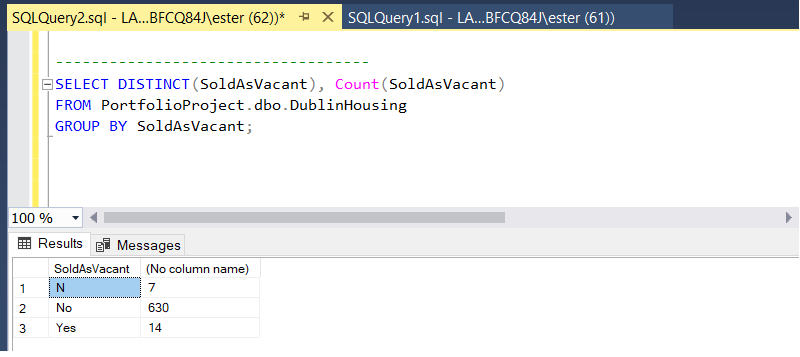 In my data I have 7 fields where answer was putted as 'N' instead of 'No'. Once again, if I would need to proceed with analyse of properties sold as vacant, this type of answer would case me an issue.
In my data I have 7 fields where answer was putted as 'N' instead of 'No'. Once again, if I would need to proceed with analyse of properties sold as vacant, this type of answer would case me an issue.
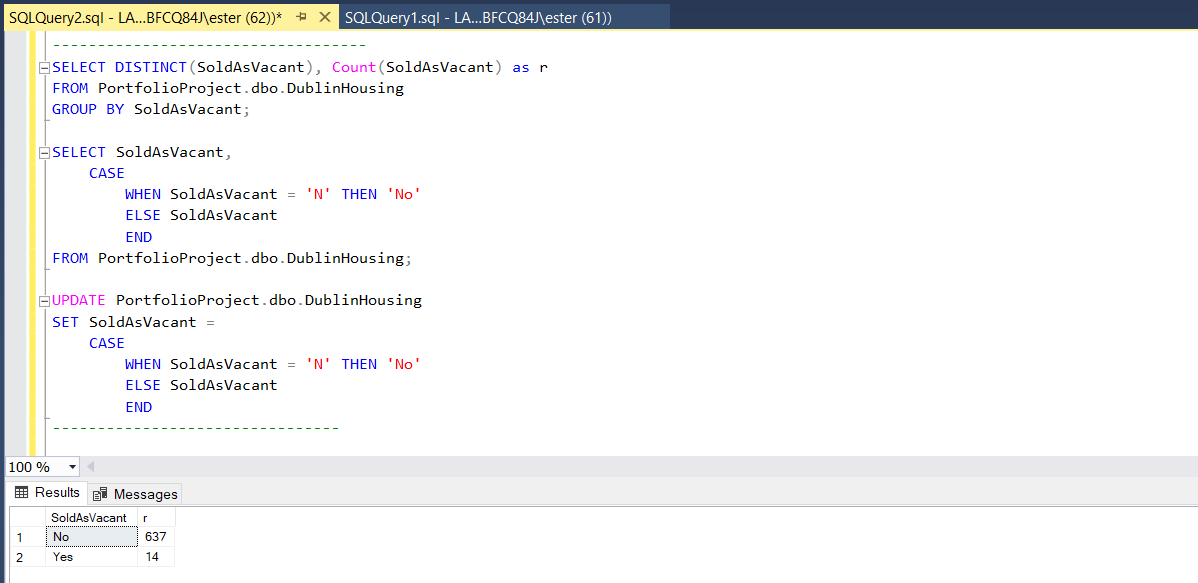
I selected 'SoldAsVacant' and use CASE condition to change fields and apply one uniform apperance.
Duplicates
Checking for duplicates (and I mean, 100% duplicated row, not few, common fields).
Starting from adding a row number and partitioning table on unique values for each row (I could use ‘UniqueID’ column but data might be entered twice and receive new ‘UniqueID’ number, therefore I will use other columns as references).
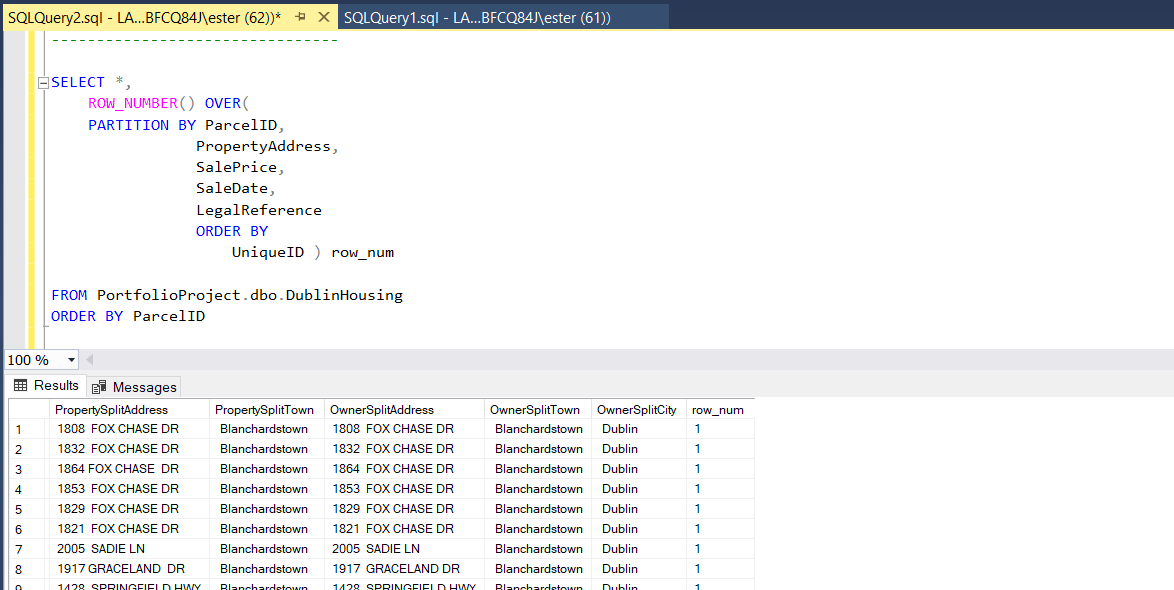
I took 'ParcelID', 'PropertyAddress', 'SalePrice', 'SaleDate', 'LegarReference' and now, in last colum of the table I have row number which is telling me how many times this row is appering in my data.
If row number will be greater than 1, I will investigate rows and if they all match, I will understand that this rows are duplicates.
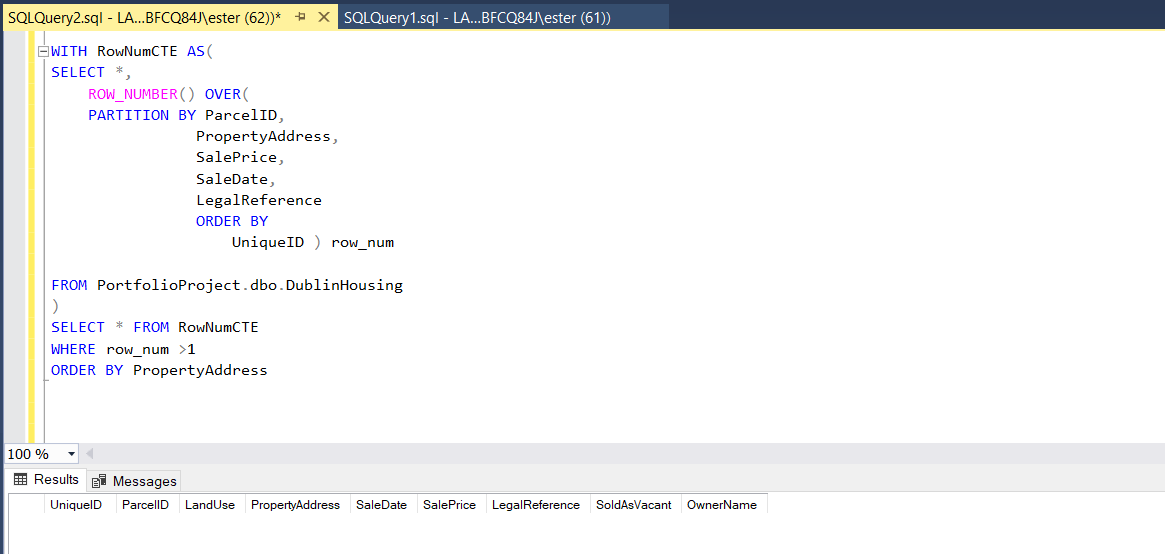
There are no rows with values for a row number > 1 which means, there is no duplicates in a data.


